Extracting Information from Scanned Documents with LLM Vision Models
Dhaval Nagar / CEO
We recently experimented on a project to extract specific information from scanned documents. By leveraging the latest Large Language Models (LLMs) with Vision capabilities, we were able to extract meaningful information efficiently and cost-effectively. This approach demonstrates the growing potential of LLM Vision Models in transforming traditional paper-based processes into more accessible digital formats.
With the use of advanced LLMs, businesses can process large volumes of scanned documents more accurately and with fewer resources. These models not only improve the accuracy of data extraction but also help in reducing the costs associated with manual processing, providing a scalable solution for various industries.
Tech Stack
Claude 3 family of models has reasonably good vision capabilities, better performance and they are cost effective. We decided to use Claude 3 Haiku for the initial testing. Depending on the use case, we prefer to use Serverless services to keep the solution scalable but cost-efficient.
- LLM Model: Amazon Bedrock with Claude 3 Haiku
- Cloud Storage: Amazon S3
- Database: Aurora MySQL
- Compute: Lambda with Step Functions
Output
Let's look at few of the example scans and their output. The input resolution is adjusted to around 1000 Tokens for each of the following images. That is just to calculate the cost of processing per image.
Note: Some of these images were taken from Google Image search.
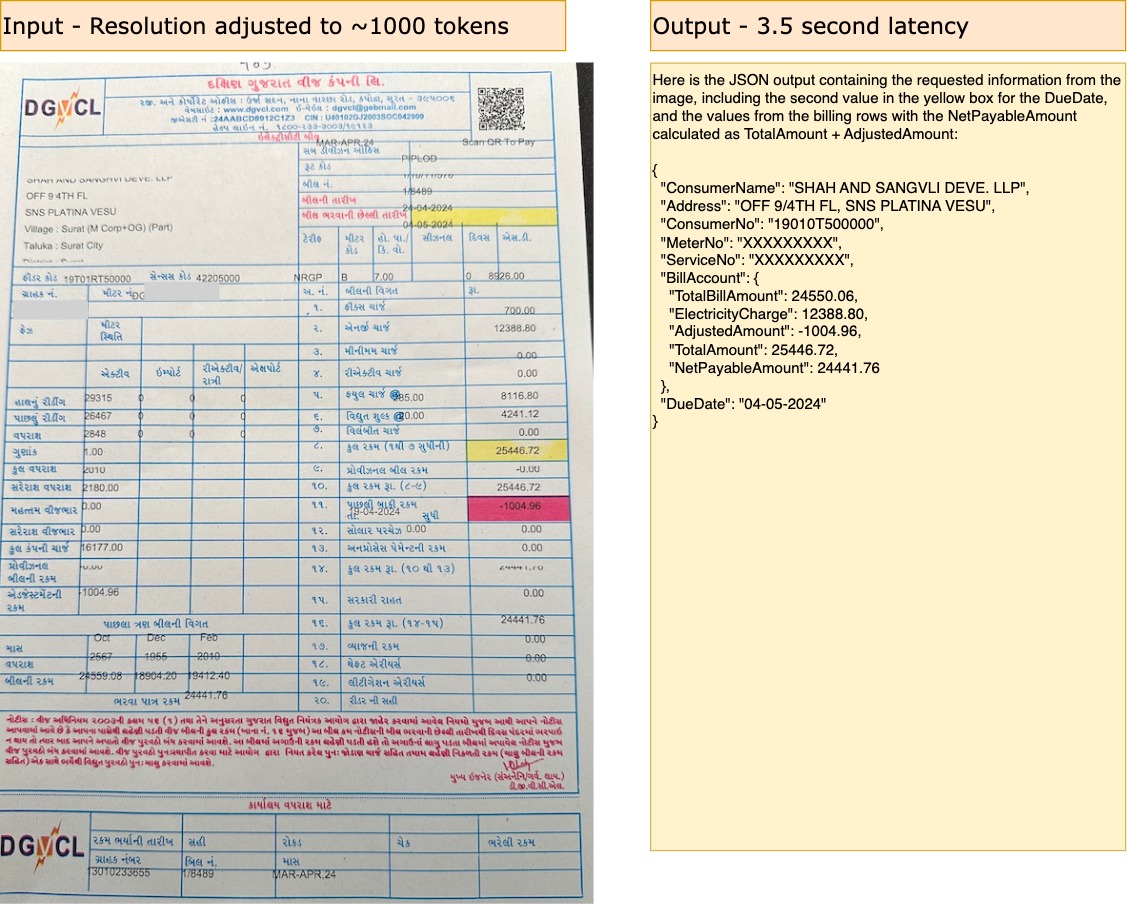
Electricity Bill in local Gujarati Language
The copy of the bill is uploaded a mobile photo for further processing. The input prompt is adjusted to extract only meaningful information along with doing a math as well. So instead of just parsing, I am also parsing and doing the sum to derive new value, NetPayableAmount.
Permanent Address Number (PAN) Photo Copy
This is a photo taken from camera. The image is of my father's PAN card. In several tries, it detects the same information consistently.

FedEx Receipt Copy
This is a sample copy for a FedEx transfer receipt. The image is pretty clean and has limited information. However, the handwriting is difficult to read. In repeating attempts, the output was pretty consistent.

Fax Copy
This is a financial transaction copy, very old one. If you look at the structure of the form and the scanned image - it's very well structured and most importantly it's computer input and not handwritten. However, from the scanning point of view, we had to adjust the prompt so that it can consider this entire form as a multi-page form and generate the JSON accordingly.

Pilot Paperwork Sheet Copy
This was by far the most complicated scan. The scanned page had medium resolution and text are hand-written, difficult to read even for a person. For this, instead of scanning the whole image we only wanted to extract certain fields so the prompt was adjusted to focus and extract only those values. Depending on the hand-writing, it was making some consistent errors in parsing, but mostly for the descriptive texts.

Cost and Performance
Newer LLMs are now supporting multi-model inputs like Text, Audio and Images. This opens up new category of applications that previous needed specific process flow. The idea of this use case was to highlight how efficiently we can extract complex information without using infrastructure and services like OCR and pre-trained ML Models.
Anthropic Claude 3 Haiku is currently priced at $0.00025 per 1000 Tokens. In comparision, Google Gemini 1.0 Pro Vision model charges $0.0025 Per Image. For use cases like this, where expected output is pretty much same from different models, cost per use and performance becomes critical parameters for scaling.
Summary
We are still scratching the surface of what all can be done using latest and greatest LLM Models. I believe, the number of applications will grow multi-fold in near future where traditionally complex processes will become much easier to do, with just an API Call.
