Case Study - Leveraging AWS Serverless and (Gen)AI for Textile Pattern Search
- Type
- Case Study
- Year
- Category
- AWS Bedrock Gen AI, Anthropic Claude 3, AWS Serverless
We recently explored a use case with good success. I belong to the Textile Hub of India - Surat. There are a lot of textile industries and each of them uses different ways to operate their business. Most of these companies have a collection of their private and customer provided design patterns for the garment printing.
Over years, some of these companies have accumulated hundreds and thousands of print patterns, mostly stored in their private storage systems.
As Andrew Ng mentioned few months back, this particular use case is part of Long Tail of Problems that can now be effectively solved using Modern LLM capabilities.
Andrew Ng: Opportunities in AI - 2023
Few years back, this use case would have required a team of experienced ML engineers, training a model to classify the patterns, infrastructure, cost and time.
Using capabilities of powerful LLMs, this use case took just a few days to validate the outcome, end-to-end. We processed and identified close to 300 unique patterns, from a small set of their designs .
The Problem
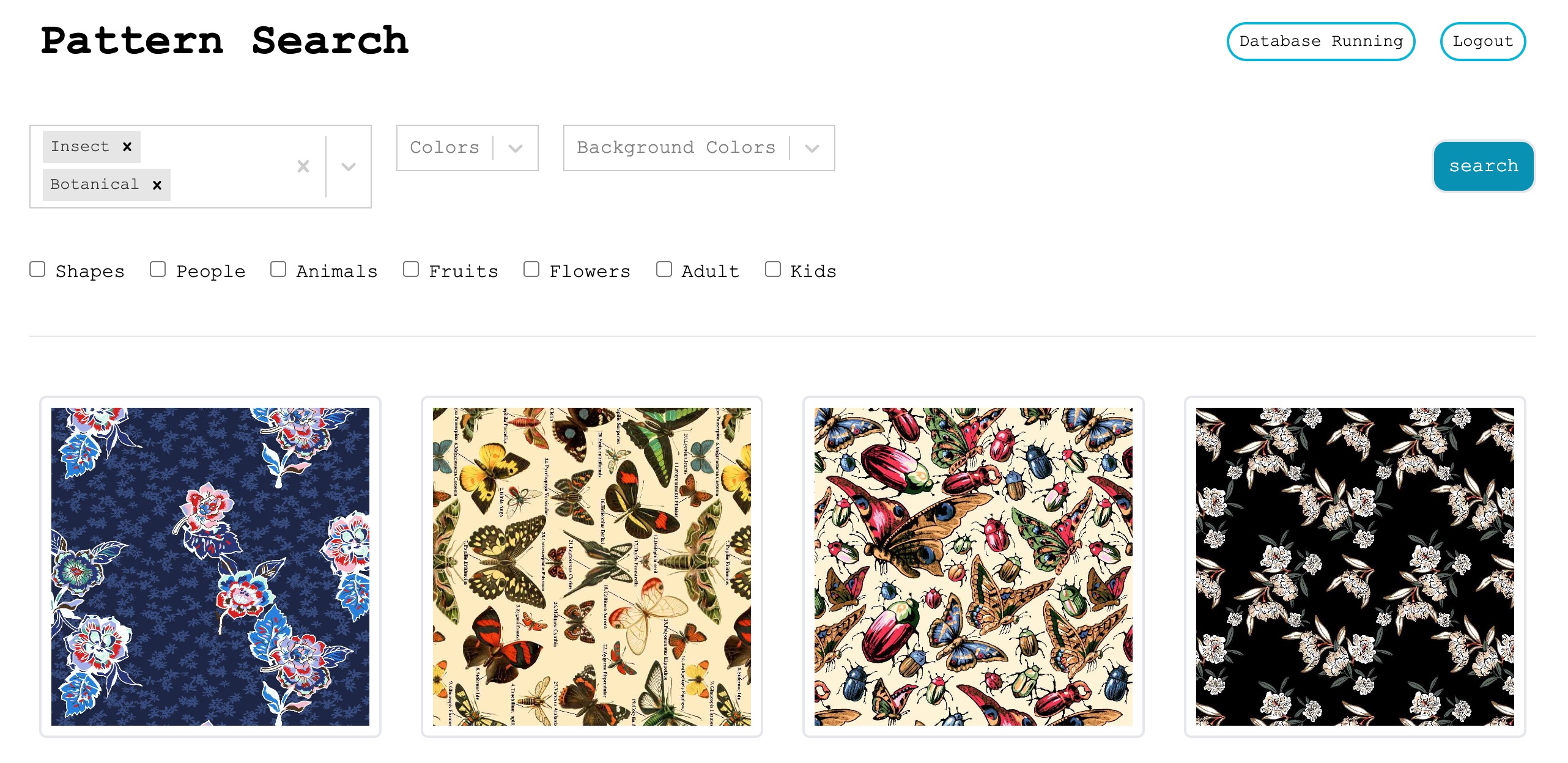
One of our customers runs a garment printing house for past 15 years. They have accumulated around 100TB worth of pattern files in the high-definition format, stored locally in their private facility. They recently shared a particular problem with us - it is very difficult to find prints based on certain properties or attributes, for example, blue floral prints or kids print with yellow background.
Usually every few months, based on season change, they create new set of patterns, which requires referring to past patterns and creating fusion prints.
Digital fabric printing files are usually in the TIFF format, with minimum resolution of 150 DPI and the file could be in GB. Most prints are in the 3600x3600 resolution with 300 DPI.
They prefer RGB color codes for the precise color output. Their graphics monitors are usually calibrated to the digital fabric printer, but this is to improve the accuracy of color in the final print.
To find proper prints, they have to rely on the manual scan through the images in the storage drives or lookup recent customer orders. Searching through the vast number of prints stored across multiple storage devices in short time is also another challenge.
Technical Challenges
Besides the business challenges, there were some technical challenges as well.
- Storage Cost: Uploading and keeping these much amount of data in the cloud was not cost effective. They needed backup but not for the full data set. So the solution needs to use the minimal Cloud infrastructure for the cost reasons.
- Attribute Tagging: Looking up each image and tagging with correct attributes is not a practical solution. Attributes can vary from time to time and sometimes they find new attributes for older images as well. So the solution needs an ability to re-process the existing images.
- Database Management: Once we generate required attributes, we need to store these attributes along with more information in a structured format so that it can be easily accessible. Storing these attributes in SQL-based database was the reliable option. But we needed to minimize the overall infrastructure hosting and management cost.
Current Solution
We iterated on number of options and settled on the following combination that worked optimally.
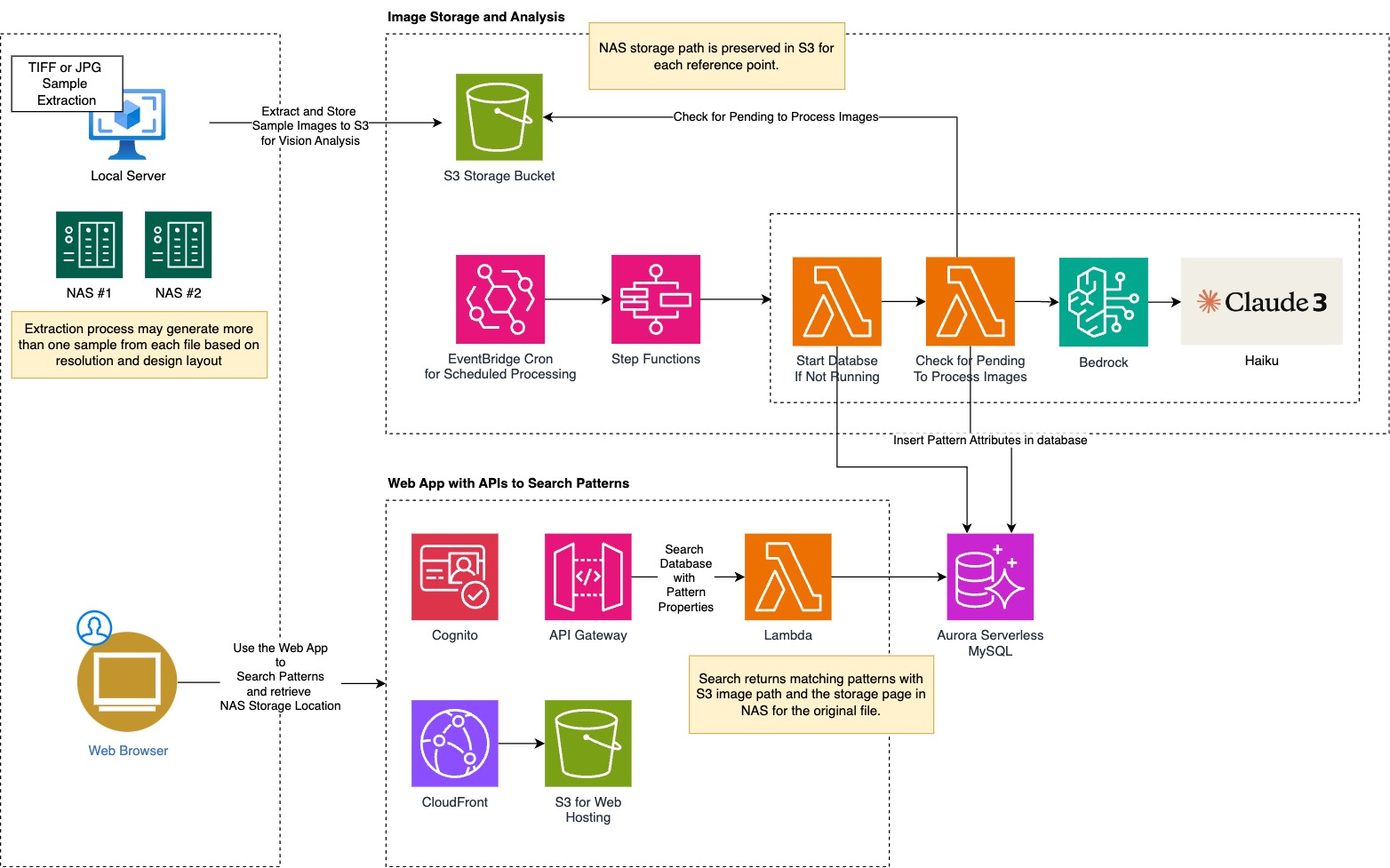
We divided the overall solution into two phases 1) Image Downsampling and Attribute Extraction and 2) Attribute Database and Application hosting
Image Downsampling and Processing
Image Downsampling: We decided to process original files by extracting a 1024x1024 dimension sample. It balances the need for detail with the practicality of processing and storage requirements. This strategy ensures that significant pattern properties are retained without the overhead of handling and managing large image files, which is crucial given the overall volume. We processed the images locally and then only uploaded the sampled images to Amazon S3 for property extraction.

We used sharp npm library to resize and extract sample regions from pattern files. This extraction is done on the local system and then the sample files are uploaded to Amazon S3 for further processing.
LLM Vision Model: Leveraging the latest Large Language Models (LLMs) for vision is a forward-thinking choice. LLMs have shown remarkable capabilities in understanding and generating textual descriptions from images, which can be more nuanced and detailed compared to traditional image analysis models. This choice allowed us for extracting richer, more accurate attributes from the prints. And it was fairly easy to experiment with various prompts to extra final output. We used Claude 3 Haiku model on Amazon Bedrock.
For more reference use this Claude 3 documentation.
Anthropic recently launched the Claude 3 family of vision-enabled models: Claude 3 Opus, Claude 3 Sonnet, and Claude 3 Haiku.
Soon after the announcement, AWS made the Sonnet and Haiku available on Amazon Bedrock. We played with Claude 3 models and realized their excellent vision and property extraction features. Due to our lower sampling size, the overall cost of using the Haiku model was pretty low and manageable.
For example, here is what we get for our sample prompts as JSON output.

And it generates the following output:
{
"image_analysis": {
"pattern": ["animal", "leopard"],
"colors": ["orange", "black", "brown"],
"backgroundColors": ["orange"],
"hasShapes": false,
"hasPeople": false,
"hasAnimals": true,
"multiColor": true,
"adultPrint": true,
"kidsPrint": false,
"hasFlowers": false,
"hasFruits": false,
"hasStripes": false
}
}Initially the idea was to use the conventional Image Analysis model and extract required image properties. We used Amazon Rekognition but it didn't work as expected for our use case.
Here is the sample output from Amazon Rekognition, compared to the LLM property extract. You can clearly see the distinction between the two. For the given use case, we needed something more powerful yet simple to use. Amazon Rekognition is very powerful service, but not suitable for our use case, we needed a more creative pattern extraction.

Every Vision Model has slightly different processing capabilities. Here are some best practices while using Claude 3 Vision capabilities.
- Image clarity: Ensure your images are clear and not too blurry or pixelated.
- Image placement: Claude works best when images come before text. In our use case, we noticed it was interpreting images well if they are placed before the text prompt.
- Prompt instruction: We iterated through several prompts to ensure that the analysis is concise and returns expected output.
- Multiple images: Claude 3 supports up to 5 images, we used only 1 image at a time.
- Image cost: Assuming your images are within expected dimension, you can estimate the number of tokens used via this simple algorithm: tokens = (width px * height px)/750.
Attribute Database and Application Hosting
Aurora Serverless V1: We decided to go with MySQL Serverless option - AWS Aurora Serverless V1 for MySQL is a sound decision for several reasons. It automatically scales capacity with the demand, which is perfect for our use case where print search operations are not constant. Paying for only the resources used during active database operations can significantly reduce costs, and we don't need to run the whole database full day. Aurora offers high performance and availability, which are essential for business-critical applications.
AWS Serverless: Considering the overall use case of this application we were confident that Serverless architecture is the best and optional way to host the overall solution.
- Amazon S3 to store and show extracted images
- Amazon S3 and CloudFront to host the Web Application
- Amazon Cognito for the user authentication (fixed users no direct sign up)
- Lambda and API Gateway for the Database Search APIs
Cost calculations
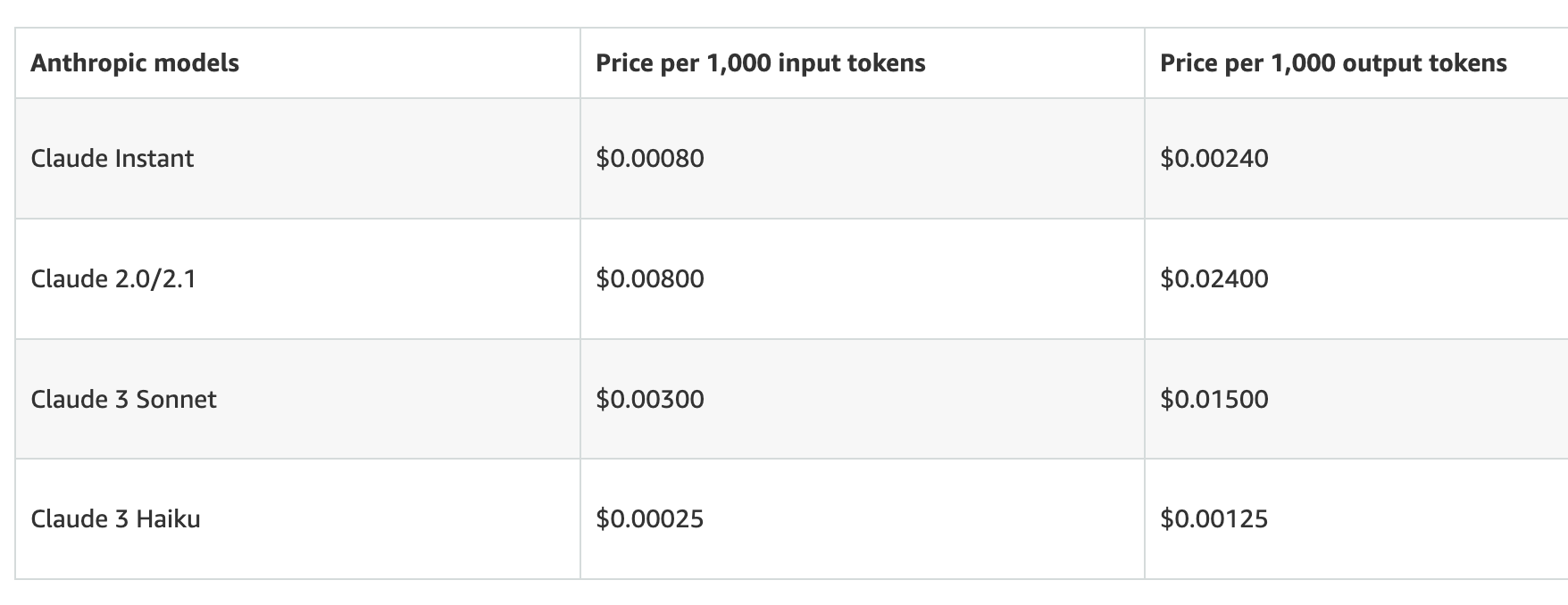
Claude 3 Haiku with Bedrock
Using LLM Models at scale can be very expensive, especially if you do not optimize your tokens properly. In our case, the biggest use was the input images. We already had pre-calculated the image dimension to input tokens. So our input image were optimal against the Claude 3 Haiku model (in future we will re-try with Sonnet or Opus with better extraction prompts).
With 10,000 sample images and 1024x1024 dimension, each prompt including image and text was taking roughly 1600 Input tokens and 150 Output tokens.
// Token Cost Per 1000 * (( Total Images * Expected Input Tokens) / 1000)
0.00025 * ( ( 10000 Files * 1600 Input Tokens) / 1000) = $4
// Token Cost Per 1000 * (( Total Images * Expected Output Tokens) / 1000)
0.00125 * ( ( 10000 Files * 150 Output Tokens) / 1000) = $1.87
With Claude 3 Haiku current token pricing, is around $6 for the image analysis. Although, this was just for the image analysis, it was still very minimal. Yes, with large number of images, this cost will increase, but we can optimize the number of images based on the similar properties. Also, not all images required 1024x1024 area, there are some patterns that can be easily captured with 512x512 dimension.
Aurora Serverless V1 MySQL
With 10,000 sample images, we are using around 700 bytes per record. Database is expected to be used anytime from Monday to Sunday, usually the printing houses are working full week, but the amount of usage is expected to be minimal.
Web Hosting and APIs
Amazon CloudFront and S3 will be almost free to use. With 10,000 sample images stored in S3 Intelligent Tier, it's roughly 5.5 GB with the expected access rate of 10-15% images per month, based on search patterns.
1 frequent access multiplier x 6 GB = 6.00 GB (total frequent access storage)
Tiered price for: 6.00 GB
6 GB x 0.023 USD = 0.14 USD
Total tier cost = 0.138 USD (S3 INT Storage, Frequent Access Tier cost)
API Gateway HTTP APIs is $1 USD Per Million requests. Considering average 15,000 API calls per months:
15,000 requests per month x 1 unit multiplier x 1 billable request(s) = 15,000 total billable request(s)
Tiered price for: 15,000 requests
15,000 requests x 0.000001 USD = 0.02 USD
Total tier cost = 0.015 USD (HTTP API requests)
HTTP API request cost (monthly): 0.01 USD
Do note that the data transfer cost (APIs and S3) is not included in the above calculations.
Next Steps
We identified close to 300 unique patterns with our extracted images and improved prompt. This was a limited-scope use case, the calculations and scope of optimization will increase if we increase the total number of sampling images from 10,000 to 100,000. There are few additional concerns that we found during this phase:
- Large Non-Repetitive Patterns: Some designs are just too large to fit in the 1024x1024 sample frame. So we have decided to take 3-5 frames from those large pattern files and use that instead of using just one sample.
- Pattern Naming: There is some difference between how the business users identify these patterns vs how the LLM has identified these patterns. This is easy to do with maintaining a mapping of keywords for each print types.
Our next implementation is to generate new patterns (PatternFusion) based on the selected patterns and additional parameters.